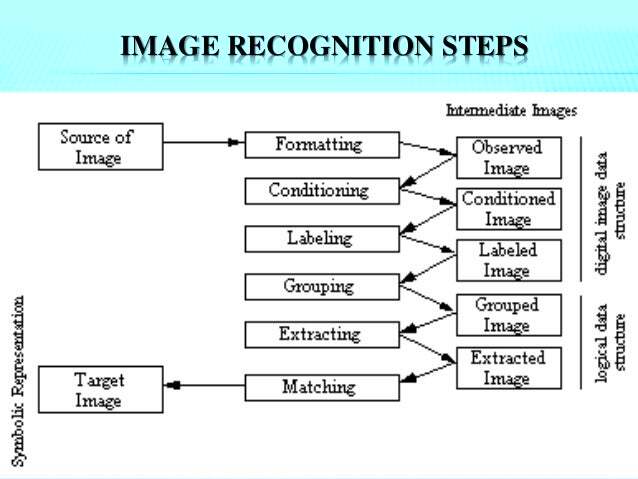
Image recognition models are powerful tools used in machine learning and artificial intelligence (AI) to analyze and identify objects or patterns in images. These models play a crucial role in various applications, such as self-driving cars, medical image analysis, security systems, and even social media. By training these models on large datasets, they can learn to distinguish between different objects, animals, people, and even emotions based on visual cues. The goal is to build a system that can recognize and classify images with accuracy, making it valuable for both businesses and technology development.
Understanding the Basics of Image Recognition
Image recognition is a type of computer vision that enables machines to interpret and understand visual information. It involves detecting and classifying objects within an image, similar to how humans can recognize different items just by looking at them. This process is carried out through algorithms that learn from data and make predictions based on learned patterns.
At its core, image recognition consists of three key steps:
- Preprocessing: Cleaning and transforming raw image data into a usable format.
- Feature extraction: Identifying key characteristics or features of the image that help in recognition.
- Classification: Assigning the image to a category based on the features extracted.
These steps are often carried out by deep learning models like Convolutional Neural Networks (CNNs), which have proven effective for handling visual data due to their ability to recognize spatial hierarchies in images.
Also Read This: Can Depositphotos Be Used on Social Media? Guidelines for Marketers and Creators
Choosing the Right Dataset for Training
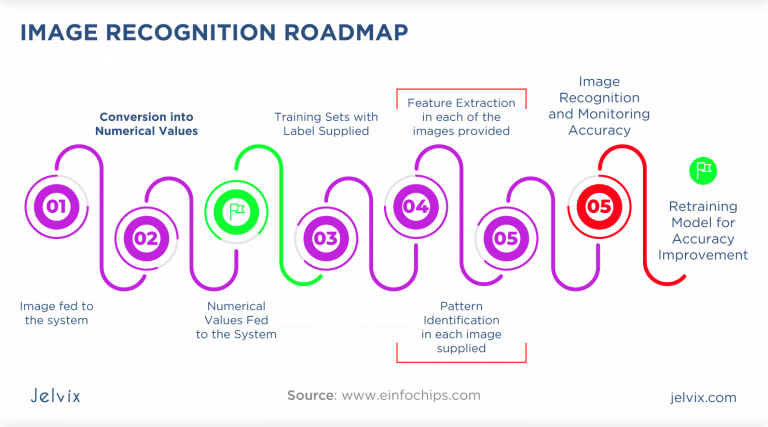
When training an image recognition model, one of the most important decisions is selecting the right dataset. The dataset should be large, diverse, and representative of the types of images the model will encounter in real-world scenarios. A good dataset allows the model to generalize well and avoid overfitting, where the model memorizes the training data without learning to apply the knowledge to new, unseen images.
Consider these factors when choosing a dataset:
- Size: A larger dataset typically improves the model's performance. Aim for tens of thousands to millions of labeled images.
- Diversity: The dataset should include various image types, angles, lighting conditions, and backgrounds.
- Labeling: Ensure that images are correctly labeled with accurate tags, as incorrect labels can negatively affect model accuracy.
Some popular datasets for image recognition include:
| Dataset | Description | Usage |
|---|---|---|
| CIFAR-10 | Contains 60,000 32x32 color images in 10 classes. | General image classification tasks. |
| ImageNet | Contains over 14 million images across 21,000 categories. | High-quality model training, especially for deep learning models. |
| COCO | Includes over 300,000 images for object detection, segmentation, and captioning. | Advanced image recognition tasks. |
Choosing the right dataset is essential for ensuring your image recognition model is both accurate and reliable. Be sure to evaluate the dataset's quality, size, and diversity before using it for training.
Also Read This: Is Getty Images a Trustworthy Source for Stock Photography?
Preparing the Data for Image Recognition
Before you can start training an image recognition model, the data needs to be prepared. This process involves several steps to ensure that the images are clean, standardized, and ready for use. Good data preparation is crucial to the success of your model, as it can significantly impact its performance.
Here are the key steps involved in preparing the data:
- Data Collection: Gather a large and diverse set of images that represent the categories you want your model to recognize. The more varied the images (in terms of background, lighting, and object angles), the better your model will generalize.
- Data Labeling: Label your images correctly by associating them with their corresponding class. Accurate labeling is crucial because poor labels can confuse the model and reduce its accuracy.
- Data Augmentation: To enhance your dataset, consider using data augmentation techniques like rotation, flipping, and scaling to create new versions of existing images. This helps the model recognize objects from different perspectives.
- Data Normalization: Ensure that all images are standardized in terms of size and pixel values. Often, images are resized to a fixed dimension (e.g., 224x224 pixels), and pixel values are normalized to a range, such as 0 to 1.
By following these steps, you ensure that your model has the best possible data to learn from, which ultimately leads to better performance when recognizing images.
Also Read This: How to download Wireimage Downloader without watermark for free
Selecting and Configuring the Model Architecture
Choosing the right architecture for your image recognition model is crucial because different architectures excel at different types of image recognition tasks. In recent years, deep learning models, especially Convolutional Neural Networks (CNNs), have become the go-to choice for image recognition tasks due to their effectiveness in extracting features from images.
When selecting a model, consider the following:
- Model Complexity: Simpler models may work well for basic tasks, while more complex models, like deeper CNNs or architectures like ResNet or Inception, are better suited for handling more complicated recognition tasks.
- Pre-trained Models: If you're short on data or computational resources, you can opt for pre-trained models. These models are already trained on large datasets like ImageNet and can be fine-tuned to suit your specific needs.
- Transfer Learning: This technique involves using a pre-trained model as a starting point and retraining it on your dataset. It’s especially useful when working with small datasets.
Here’s a quick look at some popular model architectures:
| Model Architecture | Advantages | Best Use Cases |
|---|---|---|
| ResNet | Handles deeper networks efficiently, prevents vanishing gradients. | Complex image classification tasks with large datasets. |
| VGG | Simple architecture with easy-to-understand layers. | Image classification with moderate complexity. |
| Inception | Can process images at different scales and resolutions. | Tasks with multi-scale images and varying input sizes. |
Once you’ve selected the right architecture, it's time to configure the model by setting hyperparameters, such as learning rate, batch size, and number of epochs. Fine-tuning these settings will help optimize the model for better performance.
Also Read This: Blurring Images in Paint
Training the Image Recognition Model
Training an image recognition model involves feeding prepared data into the model and adjusting its parameters to minimize errors. This is the phase where the model learns from the data by iterating over the images and adjusting weights to improve accuracy.
The training process typically follows these steps:
- Model Initialization: Initialize the model with random weights, which will later be adjusted during training.
- Forward Propagation: Pass input images through the network to make predictions (i.e., which category the model thinks the image belongs to).
- Loss Calculation: Compare the model's predictions to the true labels to calculate the loss (error). The goal is to minimize this loss by adjusting the model's weights.
- Backpropagation: Use backpropagation to calculate the gradient of the loss with respect to the model’s weights. This step helps to update the weights in the direction that reduces the loss.
- Optimization: Use an optimizer like Adam or SGD (Stochastic Gradient Descent) to update the model’s weights during training based on the calculated gradients.
During training, it's important to monitor the model’s performance using metrics like accuracy and loss. You can use techniques like cross-validation to ensure that the model is not overfitting (i.e., memorizing the training data) and can generalize well to new, unseen images.
Training can take time, depending on the dataset size, model complexity, and computational resources. But with the right approach and consistent tuning, your image recognition model will gradually improve and achieve better recognition accuracy.
Also Read This: Is iStock Legitimate? An Honest Review of the Popular Stock Photo Platform
Evaluating and Fine-Tuning the Model
Once the model is trained, it’s time to evaluate how well it performs on unseen data. Evaluation helps to understand whether the model is making accurate predictions or if there are areas for improvement. Fine-tuning the model ensures that it continues to improve and is well-optimized for the task at hand.
The evaluation process involves using a separate validation or test dataset, which the model hasn’t seen before. Here are the key steps to evaluate and fine-tune your model:
- Performance Metrics: Common metrics for evaluating image recognition models include accuracy, precision, recall, F1-score, and confusion matrix. These metrics provide insight into how well the model classifies images.
- Cross-Validation: Use k-fold cross-validation to assess the model’s performance across different subsets of the dataset. This helps ensure that the model is not overfitting and can generalize to new data.
- Error Analysis: Look at where the model is making mistakes. Are there specific classes where it consistently fails? Understanding these errors can guide your fine-tuning efforts.
- Hyperparameter Tuning: Fine-tune hyperparameters such as learning rate, batch size, and number of layers. A small change in these settings can lead to a significant improvement in model performance.
Fine-tuning also involves techniques like dropout and regularization to reduce overfitting, especially when working with complex models or small datasets. The goal is to get the model to perform optimally while ensuring it generalizes well to unseen data.
Also Read This: Understanding Copyright and Licensing: Downloading 123RF Images
Implementing the Trained Image Recognition Model
After your image recognition model has been trained and fine-tuned, the next step is to implement it in a real-world application. Whether it’s for an app, a web service, or an embedded system, integrating the model involves several considerations to ensure it runs smoothly and provides accurate predictions.
Here are the key steps to implement your trained model:
- Model Deployment: Once the model is ready, deploy it in an environment where it can process real-time data. You can deploy the model on a cloud server, an edge device, or a local machine, depending on the use case.
- API Integration: If your model will be accessed remotely, integrate it with an API that allows users to send images to the model and receive predictions. This can be done using frameworks like Flask or FastAPI for Python.
- Scalability: Ensure that the model can handle a high volume of requests, especially if it’s part of a web or mobile app. Consider using containerization tools like Docker to manage and scale the deployment process.
- Performance Optimization: Depending on the size and complexity of the model, consider techniques like model pruning, quantization, or using specialized hardware like GPUs to speed up inference times.
Successful implementation requires ongoing monitoring to check the model’s performance in the real world. Be ready to retrain or fine-tune the model as new data becomes available or as the system encounters edge cases that the model wasn’t initially trained on.
Also Read This: Is 123RF a Reliable Option for Stock Photos?
FAQ
1. What is the difference between training and fine-tuning a model?
Training involves teaching the model from scratch using a large dataset, whereas fine-tuning refers to making adjustments to a pre-trained model to improve its performance on a specific task or dataset.
2. How long does it take to train an image recognition model?
The time it takes to train an image recognition model depends on several factors, including the size of the dataset, the complexity of the model, and the computational resources available. It can take anywhere from a few hours to several days.
3. Can I use a small dataset to train an image recognition model?
While it’s possible to train a model with a small dataset, the model’s performance may suffer from overfitting. Using techniques like data augmentation or transfer learning can help improve results with a smaller dataset.
4. What is transfer learning, and how does it help?
Transfer learning involves using a pre-trained model and adapting it to a new task. This approach can save time and resources, as the pre-trained model already understands basic features and patterns, which can then be fine-tuned for specific tasks.
5. How can I evaluate if my model is overfitting?
Overfitting occurs when the model performs well on the training data but poorly on validation or test data. To detect overfitting, you can track the loss and accuracy on both training and validation sets. If the training accuracy increases but the validation accuracy decreases, the model may be overfitting.
Conclusion
Training an image recognition model involves several important steps, from selecting the right dataset to fine-tuning the model for optimal performance. The entire process is iterative, requiring constant evaluation and adjustments to ensure that the model can accurately recognize and classify images. While it can be time-consuming, the results are well worth the effort, as these models can be used in a wide range of applications, from automated systems to cutting-edge technologies like self-driving cars and medical diagnostics. With the right data, model architecture, and training process, you can build a reliable image recognition system that performs effectively in real-world scenarios.
 admin
admin








