Text recognition from images, often called Optical Character Recognition (OCR), is the process of converting printed or handwritten text from images into machine-readable text. With the rise of digital content, OCR has become an essential tool in many fields, including document digitization, data extraction, and accessibility. Python, with its easy-to-use libraries and vast community support, makes it an ideal language for text recognition tasks.
This blog will introduce you to the process of using Python to read text from an image. You’ll learn about the tools and techniques needed to extract text accurately and efficiently. Whether you're processing scanned documents or extracting text from screenshots, this guide will help you get started with OCR in Python.
Why Use Python for Text Recognition?

Python is a top choice for text recognition tasks due to its simplicity and the powerful libraries available for OCR. Here are some reasons why Python is ideal for text recognition:
- Ease of Use: Python's syntax is easy to learn and understand, making it accessible even for beginners.
- Comprehensive Libraries: Libraries like Pytesseract, Pillow, and OpenCV simplify the text recognition process and enhance accuracy.
- Wide Community Support: Python has an extensive user base and a large community that continuously develops new tools and provides helpful resources.
- Cross-Platform: Python works on multiple platforms (Windows, macOS, Linux), making it versatile for various use cases.
- Integration with Other Technologies: Python can easily integrate with machine learning and data analysis tools, allowing for more advanced applications of OCR.
Python’s combination of simplicity and power makes it a great option for both beginners and experienced developers who want to implement text recognition in their projects.
Steps to Read Text from an Image Using Python
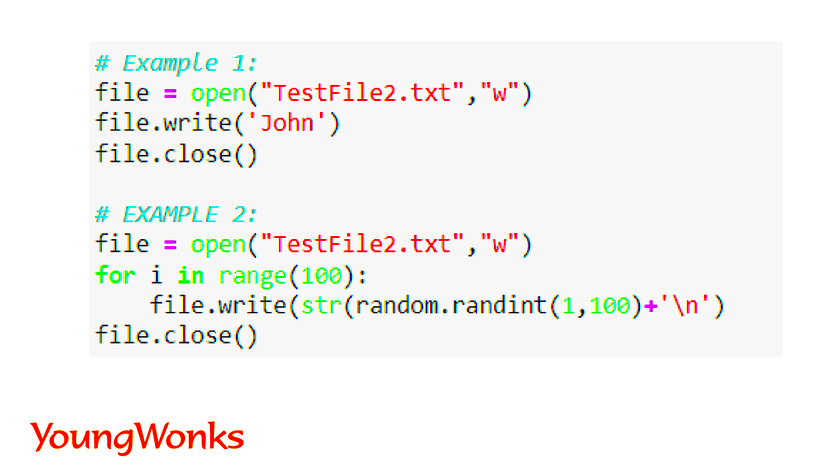
Reading text from an image with Python requires a few basic steps. Let’s walk through the entire process so you can get started quickly.
Step 1: Install the Required Libraries
To perform OCR with Python, you need to install two essential libraries: Pytesseract and Pillow. You can install them using the following commands:
pip install pytesseract pip install pillow
Step 2: Import the Libraries
After installing the libraries, you need to import them into your Python script.
from PIL import Image import pytesseract
Step 3: Load the Image
Now that the libraries are imported, the next step is to load the image you want to extract text from. Python’s Pillow library provides easy-to-use functions for image loading.
img = Image.open("image_path.jpg")
Step 4: Extract Text from the Image
With the image loaded, you can now use Pytesseract to extract the text. Pytesseract is a wrapper for Google’s Tesseract-OCR Engine, which does the heavy lifting of converting the image’s text into readable format.
text = pytesseract.image_to_string(img) print(text)
Step 5: Display the Extracted Text
Finally, after running the code, you will see the text extracted from the image displayed on the screen. Depending on the quality of the image, the accuracy of the text extraction will vary, but this basic approach provides a solid starting point.
This is a simple yet effective method to read text from an image using Python. In the next sections, we’ll look at improving accuracy and handling different image types for better results.
Installing Required Libraries for Text Recognition
To get started with text recognition in Python, you'll need a few essential libraries that make the process easier and more efficient. The most important libraries for text extraction from images are Pytesseract and Pillow. Here’s how to install them and get set up:
1. Installing Pytesseract
Pytesseract is a Python wrapper for the Tesseract OCR engine, one of the most accurate and widely used tools for optical character recognition. To install it, you can use Python’s package manager, pip. Open your command prompt or terminal and type:
pip install pytesseract
2. Installing Pillow
Pillow is a powerful Python Imaging Library (PIL) fork that allows you to open, manipulate, and process images. It is essential for loading and handling images before feeding them to Pytesseract. Install Pillow using pip with the following command:
pip install pillow
3. Installing Tesseract OCR Engine
In addition to the Python libraries, you’ll also need the Tesseract OCR engine itself, which Pytesseract interacts with. Tesseract can be downloaded from its official repository, and the installation process depends on your operating system. Below are the steps for different platforms:
- Windows: Download the installer from the official GitHub page and follow the setup instructions.
- macOS: Use Homebrew with the command:
brew install tesseract - Linux: On most distributions, you can install Tesseract using your package manager, like:
sudo apt install tesseract-ocr
After these installations, you'll be ready to start reading text from images using Python!
Preprocessing the Image for Better Accuracy
Once you’ve installed the required libraries and set up your environment, the next step is to prepare the image for text recognition. Image preprocessing is crucial for improving the accuracy of the extracted text, as raw images can contain noise, blurriness, or other factors that hinder text recognition.
1. Convert Image to Grayscale
One of the simplest yet most effective preprocessing steps is converting the image to grayscale. This removes unnecessary color information and helps the OCR engine focus on the text itself. You can easily convert an image to grayscale using the Pillow library:
gray_img = img.convert('L')
2. Remove Noise
Noise in an image can confuse the OCR engine and lead to inaccurate text recognition. You can use techniques such as thresholding or blurring to remove noise. Here’s how you can apply Gaussian Blur to reduce noise:
from PIL import ImageFilter blurred_img = gray_img.filter(ImageFilter.GaussianBlur(radius=1))
3. Adjust Image Brightness and Contrast
Sometimes, adjusting the brightness and contrast of an image can make text stand out more clearly, which helps with accurate recognition. Pillow makes it easy to adjust the image contrast:
from PIL import ImageEnhance enhancer = ImageEnhance.Contrast(gray_img) enhanced_img = enhancer.enhance(2.0)
4. Binarization
Binarization (converting the image into two colors, typically black and white) is another useful technique. It simplifies the image for the OCR engine by removing shades of gray and focusing only on the text. You can apply binarization with the following code:
binary_img = gray_img.point(lambda p: p > 128 and 255)
Preprocessing can significantly improve the OCR results. The cleaner and more focused the image, the better the accuracy when extracting text.
Using Pytesseract for Text Extraction
Now that you have your image preprocessed and ready, it’s time to extract the text using Pytesseract. This powerful tool makes it simple to get readable text from an image with just a few lines of code.
1. Import the Required Libraries
You’ll need to import Pytesseract and Pillow to load and process the image, as shown below:
from PIL import Image import pytesseract
2. Load the Image
Load the image that you want to extract text from using Pillow’s Image.open() function:
img = Image.open("your_image.jpg")
3. Extract Text Using Pytesseract
Once the image is loaded, you can use Pytesseract’s image_to_string() function to extract the text:
text = pytesseract.image_to_string(img) print(text)
4. Handling Multiple Languages
If the text in your image is in a language other than English, you can specify the language by using the lang parameter. For example, to extract text in Spanish, you would use:
text = pytesseract.image_to_string(img, lang='spa')
5. Extracting Text from Different Image Formats
Pytesseract can handle various image formats, including PNG, JPEG, and TIFF. Just make sure to load the image in the appropriate format, and the text extraction will work seamlessly.
6. Post-Processing the Extracted Text
Once the text is extracted, you can further clean or format the text as needed. This might involve removing unwanted characters, correcting spelling errors, or organizing the output into a more readable format.
With these steps, you can effectively use Pytesseract to extract text from images. The accuracy of the extraction depends on factors like the quality of the image, the text size, and the preprocessing techniques applied earlier.
Handling Errors and Improving Recognition Accuracy
While text recognition in Python can be incredibly useful, there are times when the OCR process doesn’t work as expected. Whether it's due to poor image quality, complex fonts, or low contrast between text and background, errors in text extraction are common. In this section, we’ll explore how to handle errors and improve the accuracy of text recognition.
1. Dealing with Incorrect Text Output
If the text extracted by Pytesseract is not accurate, one of the main reasons could be poor image quality. To address this, start by improving your image preprocessing techniques, such as enhancing contrast, removing noise, and converting to grayscale. Additionally, ensure that the image resolution is high enough (at least 300 DPI) for better OCR accuracy.
2. Handling Multilingual Text
Pytesseract can handle multiple languages, but if the wrong language is detected, it can lead to errors. Always specify the correct language by using the lang parameter when calling the image_to_string() function. For example:
text = pytesseract.image_to_string(img, lang='fra')
Make sure the Tesseract language packs for the specific language are installed to avoid issues.
3. Improving Accuracy with Configuration
Pytesseract allows you to fine-tune the OCR engine using configuration options. For example, you can specify certain modes like "OEM" (OCR Engine Mode) or "PSM" (Page Segmentation Mode). These settings can improve recognition, especially when dealing with images that have multiple text blocks or irregular layouts.
- OEM Modes: Control the OCR engine type (Standard, LSTM, etc.)
- PSM Modes: Adjust how Pytesseract processes the layout of the page (single block, sparse text, etc.)
4. Handling Low-Quality Images
For images with poor quality or significant distortion, using advanced techniques like image denoising or edge detection can help improve OCR results. OpenCV is a great tool to implement these techniques, especially for complex images.
Best Practices for Text Recognition in Python
To get the best results from text recognition using Python, it’s essential to follow a set of best practices. These tips will help you optimize your workflow, improve accuracy, and handle different types of images more effectively.
1. Preprocess Images Effectively
The most important step for improving text recognition is to preprocess the image before sending it to Pytesseract. Clean images are much easier to process, so apply the following techniques:
- Convert images to grayscale to reduce unnecessary data.
- Remove noise and blur the image to make the text more readable.
- Adjust contrast and brightness to enhance text visibility.
2. Use the Right OCR Settings
As mentioned earlier, Pytesseract’s OEM and PSM settings play a significant role in improving OCR accuracy. By adjusting these settings, you can optimize text extraction for various types of documents, such as forms, books, or invoices.
3. Test with Different Image Formats
Although Pytesseract supports many image formats, some may yield better results than others. Experiment with different formats like PNG, TIFF, or JPEG to find out which works best for your images. High-resolution images (at least 300 DPI) also tend to give better text extraction results.
4. Choose the Right OCR Engine
Tesseract OCR offers multiple OCR modes (LSTM, standard) and segmentation modes, depending on the structure of your document. If your document contains complex layouts, using the LSTM model will provide better accuracy. If it’s a simple document with clear text, the standard mode might be faster.
5. Validate and Clean Extracted Text
Once you extract text, it’s always a good practice to validate the output. Post-processing steps such as removing extra spaces, correcting misrecognized words, and formatting the text can save a lot of time and effort. Consider using regular expressions to clean up extracted text automatically.
FAQ
In this section, we’ll answer some of the most common questions related to text recognition in Python. These questions will help clarify some doubts and provide additional insights into optimizing the process.
1. What image formats are best for text recognition?
The best image formats for text recognition are usually lossless formats like PNG and TIFF. These formats preserve the quality of the image better than lossy formats like JPEG, which can introduce compression artifacts that hinder OCR accuracy.
2. How can I improve text recognition accuracy for blurry images?
Blurry images can be challenging for OCR. To improve accuracy, you can apply image enhancement techniques like sharpening, increasing contrast, or using denoising filters. Additionally, increasing the resolution of the image can help the OCR engine detect text more clearly.
3. Can Pytesseract recognize handwriting?
While Pytesseract works well for printed text, handwriting recognition is much more difficult. The accuracy of OCR for handwriting varies greatly depending on factors like legibility and consistency. For better results with handwriting, you may want to explore other specialized models.
4. How do I handle text recognition in multiple languages?
Pytesseract supports multiple languages, and you can specify the language of the text in the image using the lang parameter. For example, to recognize French text, use lang='fra'. Ensure the corresponding language packs are installed in your Tesseract setup.
5. What can I do if the text extraction is inaccurate?
Inaccurate text extraction could be due to various factors, including poor image quality or the wrong OCR settings. Try enhancing the image by adjusting brightness, contrast, and removing noise. Also, experiment with different OCR engine and page segmentation modes for better results.
Conclusion
Text recognition in Python using tools like Pytesseract and Pillow can significantly streamline the process of extracting text from images. By following the steps outlined in this guide, you can harness the power of Optical Character Recognition (OCR) to convert images into machine-readable text with high accuracy. While preprocessing images and choosing the right settings are crucial for optimal results, Python’s rich ecosystem of libraries and robust community support make it easier than ever to get started. Whether you are working with scanned documents, screenshots, or photographs, Python offers an efficient and scalable solution for text extraction. The key is to experiment with different configurations and image processing techniques to improve the accuracy of the recognition. With the right approach and tools, you can implement effective text recognition for various real-world applications, from digitizing documents to extracting data from forms.
 admin
admin








